重複データを除外して取得
データはテーブルの中から必要なカラムを指定して取得しますが、カラムの値が同じデータが含まれている場合があります。このような時に重複するデータを除外することが可能です。ここでは重複したデータを除外してデータを取得する方法について解説します。
重複行は除外してデータを取得するには「DISTINCT」キーワードを指定します。書式は次の通りです。
SELECT DISTINCT カラム名, ... FROM テーブル名;
重複しているかどうかの判断はデータ全体が一致しているかどうかではなく、データの中でSELECT文で取得したカラムの値が一致しているデータが対象となります。カラムが1つであればそのカラムの値同じデータ、複数のカラムの値を取得している場合はその値の組み合わせが全て同じデータです。
なお「DISTINCT」とは逆に重複するデータも全て取得する場合には「ALL」キーワードを指定します。書式は次の通りです。
SELECT ALL カラム名, ... FROM テーブル名;
ただし省略した場合と同じ結果になりますので特に記載する必要はありません。
----
では実際に試してみます。次のようなテーブルを作成しました。
create table product(name text, size text, color text);
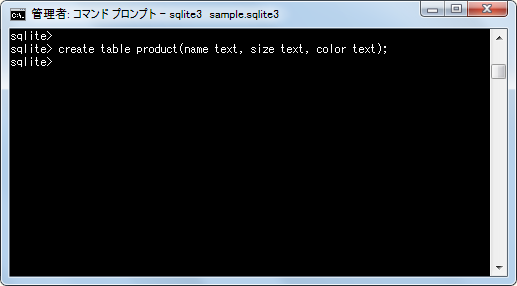
このテーブルにはいくつかのデータが格納されており、そのままデータを取得した場合には次のようになります。
select * from product;
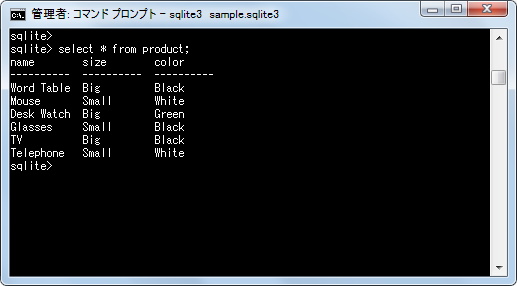
それではDISTINCTを指定して重複データを除いたデータを取得してみます。まずはproductテーブルの「size」カラムのデータを取得してみます。
select distinct size from product;
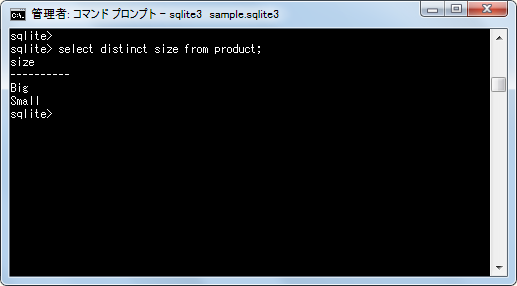
テーブルに含まれる「size」カラムの値の中で重複を除いたデータは「Big」と「Small」です。次に「color」カラムのデータを取得してみます。
select distinct color from product;
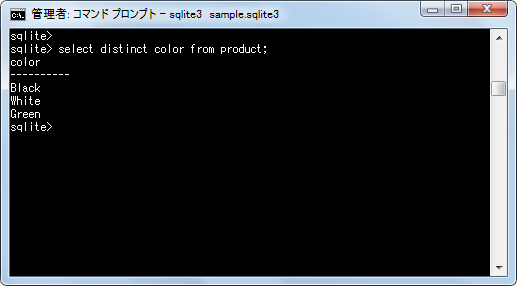
テーブルに含まれる「color」カラムの値の中で重複を除いたデータは「Black」「Whiete」「Green」です。
次に重複を除いたデータを取得する場合で複数のカラムを指定した場合を試してみます。
select distinct size, color from product;
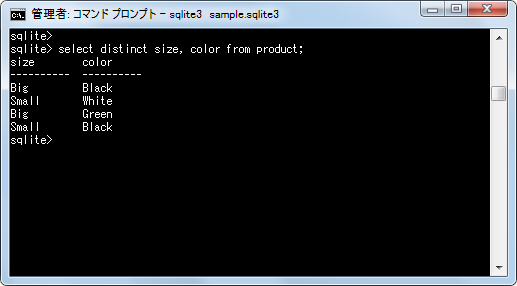
複数のカラムを指定した場合、複数のカラムの値の組み合わせが重複したデータだけが除外されますので、それぞれのカラムだけ見ると重複した値が含まれます。
このようにDISTINCTを指定することで重複を除いたデータを取得することができます。
( Written by Tatsuo Ikura )
