データをグループ化して合計や平均を計算
データの個数を調べる関数やカラム毎の値を集計する関数などを使用する時に、全てのデータをまとめて対象とするのではなく特定のカラムを値を使ってグループ化を行いグループ単位で集計などを行うことができます。ここではグループ化を行う時に使用するGROUP BY句の使い方、及びグループ化した後で絞り込みを行うために使用するHAVING句について解説します。
まずグループ化を行う方法と使い方についてです。GROUP BY句を使用する場合の書式は次の通りです。
SELECT カラム名, ... FROM テーブル名 GROUP BY カラム名, カラム名, ...;
GROUP BY句の後に指定したカラム名の値が同じものが同じグループとなります。複数のカラムを指定した場合は、値の組み合わせが同じものでグループ化されます。
少し分かりにくいかもしれないので実際の例を見て下さい。
例として次のようなテーブルを作成しました。
create table user(name text, gender text, address text);
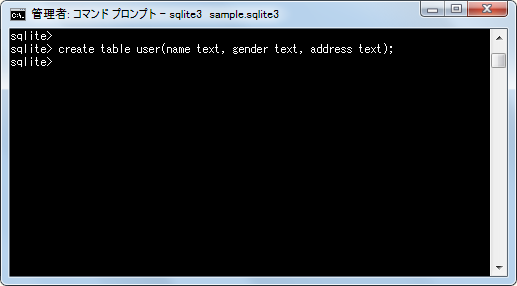
このテーブルにはいくつかのデータが格納されています。
select * from user;
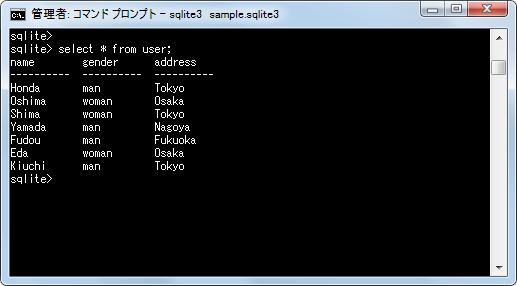
まずcount関数を使ってテーブル全体のデータの行数を取得してみます。(count関数については「count関数」を参照して下さい)。
select count(*) from user;
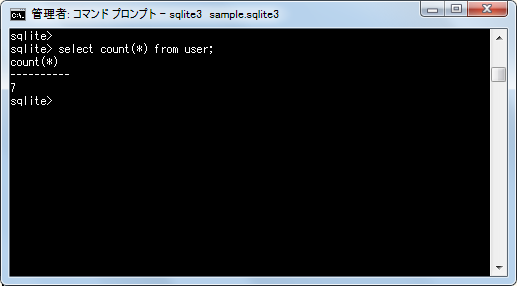
次に「gender」カラムでグループ化を行い、グループ毎に含まれるデータの行数を取得します。
select gender, count(*) from user group by gender;
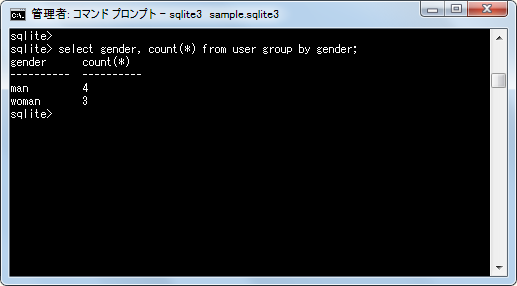
「gender」カラムに含まれる値毎にデータの行数が取得できました。同じように今度は「address」カラムでグループ化を行いデータの行数を取得します。
select address, count(*) from user group by address;
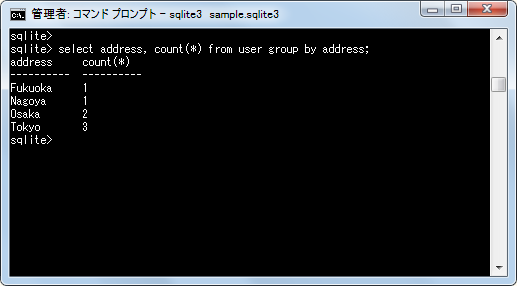
「address」カラムに含まれる値毎にデータの行数が取得できました。最後に複数のカラムでグループ化を行ってみます。「gender」カラムと「address」カラムでグループ化を行いデータの行数を取得します。
select gender, address, count(*) from user group by gender, address;
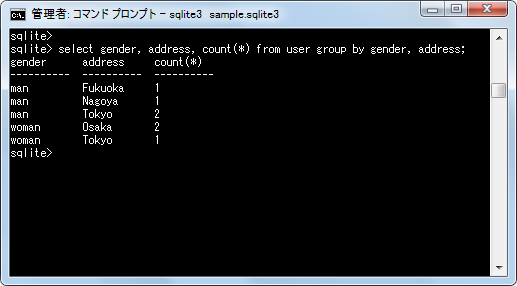
指定した複数のカラムの値の組み合わせ毎にグループ化されてデータの行数が取得できました。
今回はcount関数を使って試してみましたが、他の関数を使用することでグループ毎に値の合計値を出したり平均値を出したりすることができます。
グループ化を行う場合にもWHERE句を使って対象となるデータの条件設定を行うことができます。
SELECT カラム名, ... FROM テーブル名 WHERE 条件式 GROUP BY カラム名, ...;
この場合はまずWHERE句に記述された条件式で取得するデータを絞り込んだ上でグループ化が行われます。
それに対してグループ化を行った上で、取得するグループを絞り込むために使用されるのがHAVING句です。書式は次の通りです。
SELECT カラム名, ... FROM テーブル名 GROUP BY カラム名, ... HAVING 条件式;
グループ化が行われた結果に対して条件式が適用されますので、HAVING句の条件式に記述できるのはグループ化に指定したカラム名や、関数などを使ってグループ単位で集計した結果だけです。
それでは実際に試してみます。先ほど使用したテーブルを使います。次のようなデータが現在格納されています。
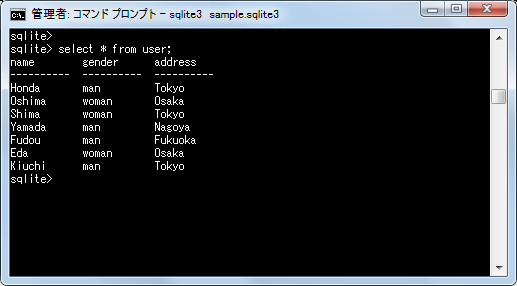
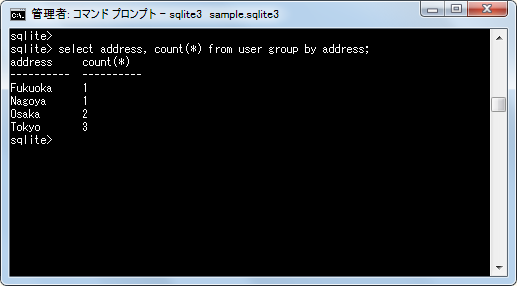
条件を設定せずに「address」カラムでグループ化を行いデータの行数を取得してみます。
select address, count(*) from user group by address;
それではHAVING句を使って「count(*)」の個数が2以上のデータだけを取得するようにしてみます。
select address, count(*) from user group by address having count(*) >= 2;
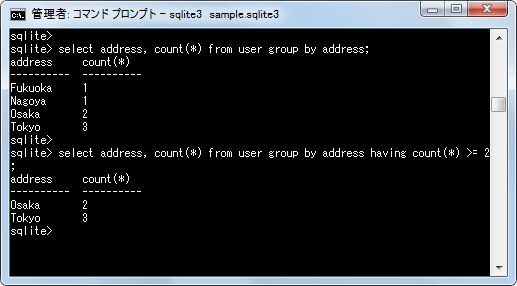
グループ化された後で取得したデータの中で条件式を満たすものだけが取得されました。このようにHAVING句を使用することで、グループ化した後のデータに対して条件式を設定することができるようになります。
( Written by Tatsuo Ikura )
