重複行を除外
広告
取得したデータの中に重複する行が含まれていた場合、重複行は除外してデータを取得することが可能です。書式は次の通りです。
SELECT DISTINCT col_name, ... FROM tbl_name;
SELECTの後にDISTINCTを付けてデータを取得すると、取得したデータの中に重複した行が含まれていた場合にはそれを除外します。この時、除外の対象となる行は、全てのカラムの値が一致している行ではなく、SELECT文で取得したカラムの値が全て一致している行です。
例えば次のように記述します。
SELECT DISTINCT name FROM goods;
上記の場合、「name」カラムの値が重複するデータは除外してデータを取得します。
DISTINCTとは逆に重複するデータも全て取得する場合にはALLを指定します。
SELECT ALL col_name, ... FROM tbl_name;
ただ何も指定しなかった場合は全てのデータを取得するため、ALLを明示的に指定することはほとんどありません。
サンプル
実際に試してみます。まず次のようなテーブルを作成します。
mysql> create table personal(name varchar(20), address varchar(20), old int);
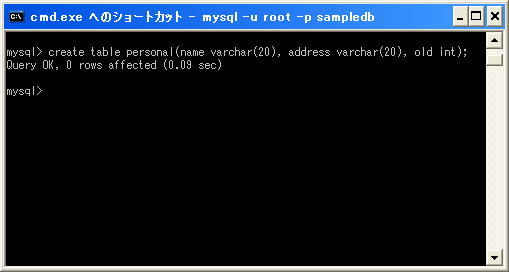
テーブルには次のようなデータを追加してあります。
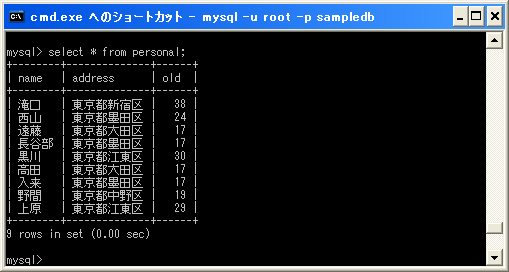
では「address」カラムの値を重複行を除外して取得します。
mysql> select distinct address from personal;
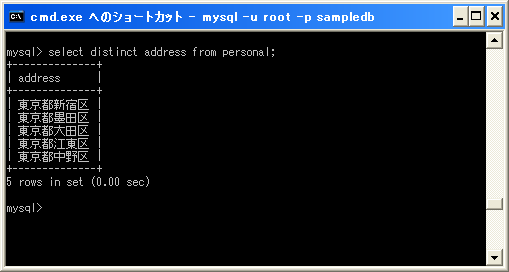
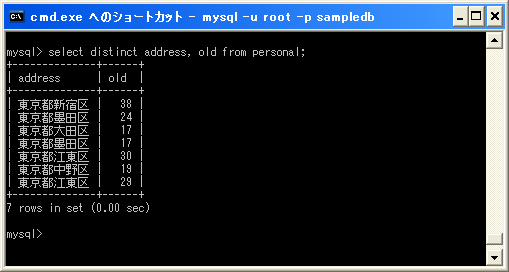
今度は「address」カラムと「old」カラムの値のペアが重複している行を除外して取得します。
mysql> select distinct address, old from personal;
( Written by Tatsuo Ikura )
