- Home ›
- MySQLの使い方 ›
- MySQLの基本構文 ›
- HERE
文字セットと照合順序
MySQLではサーバ、データベース、テーブル、カラムのそれぞれに対して文字セットと照合順序を設定することができます。ここでは指定可能な値の確認方法について確認します。
まず指定可能な文字セットの一覧は次のように入力することで取得することができます。
SHOW CHARACTER SET;
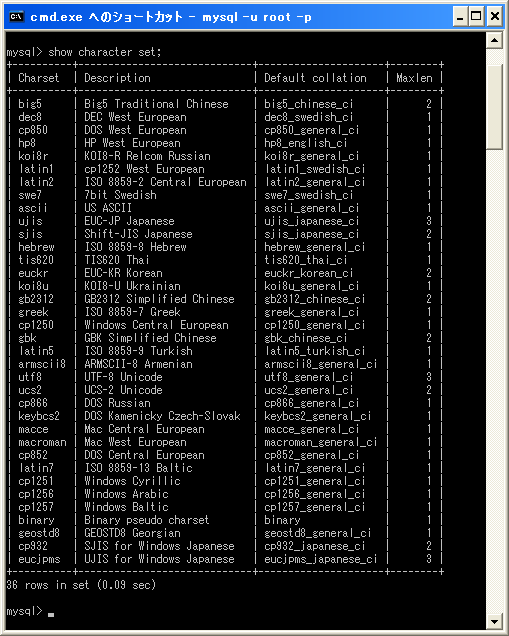
現在36種類の文字セットが用意されています。比較的使用される文字セットは次の通りです。
+----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | binary | Binary pseudo charset | binary | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | +----------+-----------------------------+---------------------+--------+
文字セットを指定する場合は「Charset」列の値である「utf8」や「cp932」を指定します。なお「Maxlen」列の値は、その文字セットで1つの文字に必要となる最大バイト数です。
また文字セット毎に照合順序が用意されています。照合順序というのは複数の値を比較する時に、どのように比較するのかを定義しているもので各文字セットにデフォルトで設定されている照合順序は「Default collation」列に記載されています。例えば「utf8」のデフォルト照合順序は「utf8_general_ci」です。
では文字セット毎にどのような照合順序が用意されているかを確認してみます。次のように入力することで取得できます。
SHOW COLLATION LIKE 'latin1%';
調べたい文字セットをLIKE式の後に'文字コード名%'と指定して下さい。例えばutf8ならば次のように入力します。
mysql> show collation like 'utf8%';
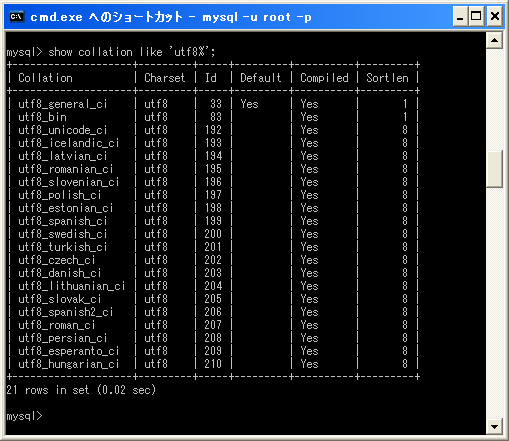
またcp932ならば次のように入力します。
mysql> show collation like 'cp932%';
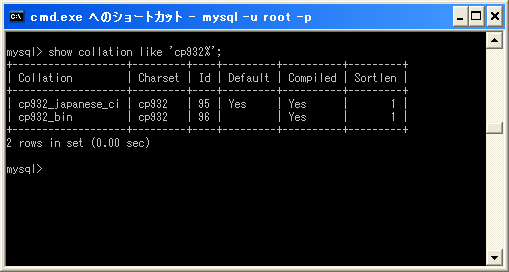
文字セット毎に用意されている照合順序は異なります。また用意されている数も違います。
文字セットの末尾が「_ci」となっているものは大文字と小文字を区別しません。末尾が「_bin」となっているものはバイナリ比較を行います。(バイナリ比較とは格納されているデータをバイナリデータと見なして数値の比較します。結果的に大文字と小文字は区別されます)。また今回は出てきていませんが末尾が「_cs」となっているものは大文字と小文字を区別します。
( Written by Tatsuo Ikura )
